



Creative Defense Against AI Crawlers: From Labyrinth to HTML Bombs

In the ongoing battle between web platforms and AI training crawlers, developers are crafting ingenious defensive mechanisms. While traditional robots.txt files served as an agreement between websites and search engines, AI companies have ignored these protocols, forcing the tech community to develop aggressive countermeasures.
The Problem: Aggressive AI Crawling
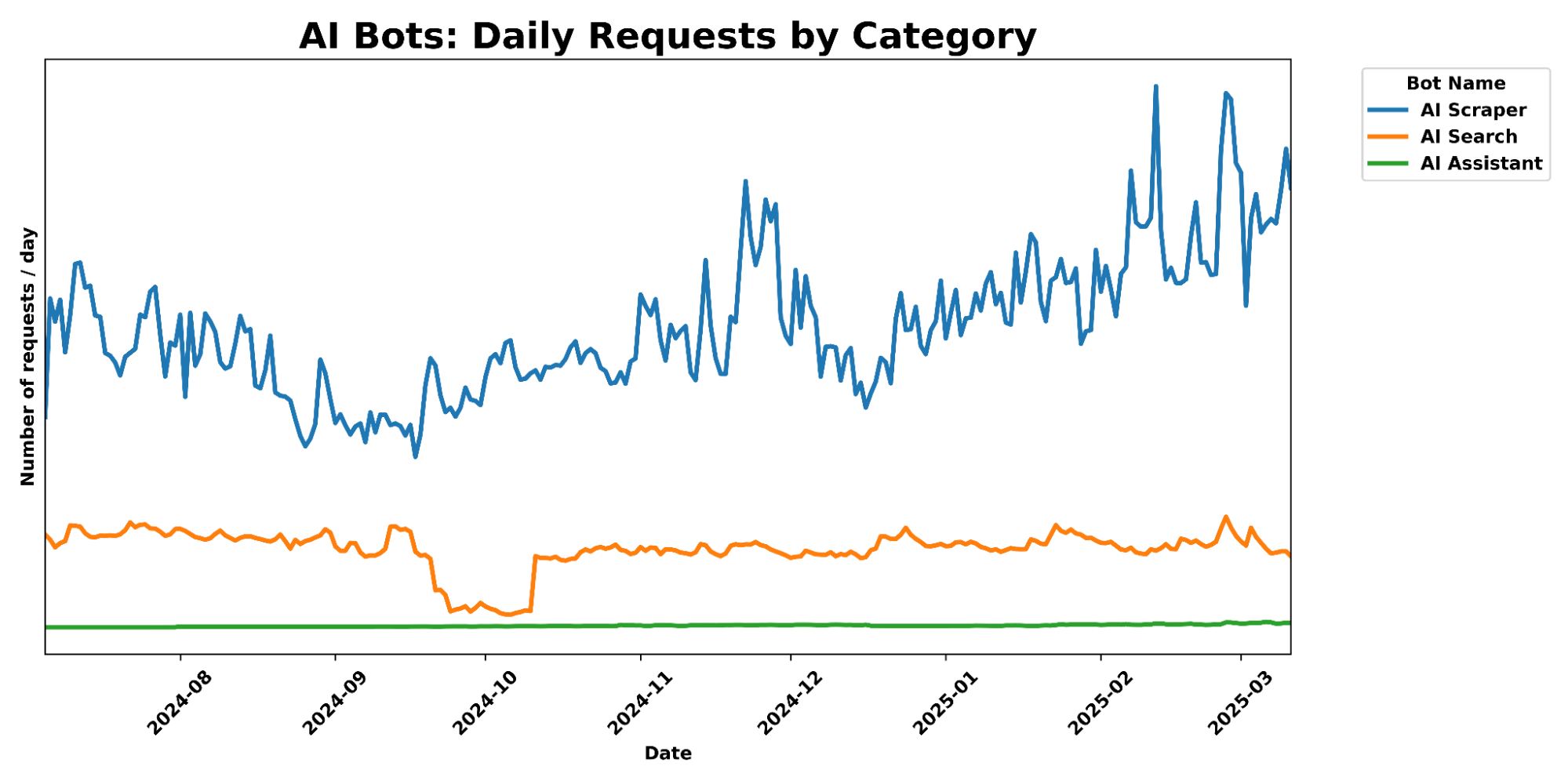
AI companies’ web crawlers are straining web infrastructure. Unlike traditional search engine crawlers that respect robots.txt directives and maintain reasonable crawl rates, AI training bots are known for:
- Ignoring crawler etiquette
- Generating excessive server loads
- Scraping content without permission or adhering to rate limits
- Consuming a large amount of bandwidth
Technical Countermeasures Emerge
Cloudflare’s Labyrinth
Cloudflare’s response to this challenge was “Labyrinth” – a defensive tool using an elegant deception strategy. When the system detects AI crawler behavior, it dynamically generates an endless maze of meaningless pages, trapping the crawler in a resource-wasting loop.
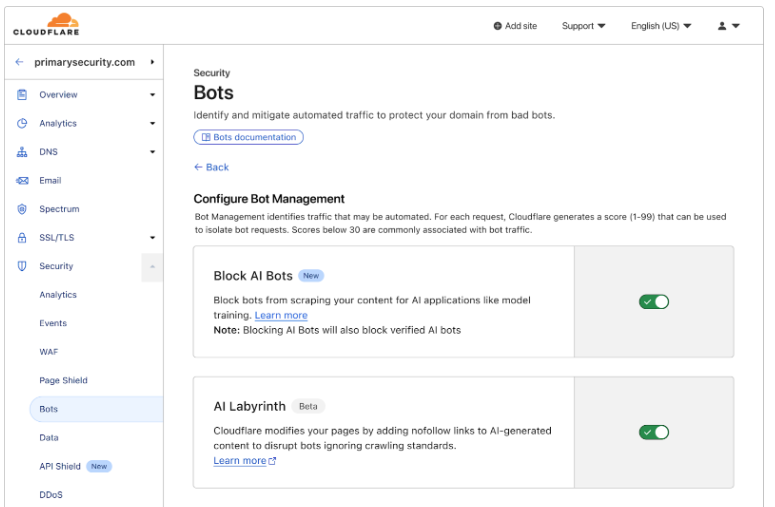
“What makes this approach particularly effective is its role in our continuously evolving bot detection system. When these links are followed, we know with high confidence that it’s automated crawler activity, as human visitors and legitimate browsers would never see or click them.“
This creates a reliable data stream for identifying new crawler patterns and behaviors, strengthening the bot detection system without impacting legitimate users. The method serves as a trap that protects content and gathers intelligence about evolving crawler techniques.
Notably, this builds upon Project Honeypot, a 2004 initiative by Cloudflare’s founders (pre-Cloudflare) that pioneered community-based bot detection through email honeypots. Labyrinth takes this concept into the AI age, creating a more dynamic and resilient system that adapts to sophisticated crawler behaviors. p.s. this is the reason why Neuralab team actively uses both CloudFlare and Kinsta cybersecurity tools for over ten years.
The HTML Bomb: A Nuclear Option
A developer known as “Ache” recently introduced a more radical solution: the HTML bomb. This ingenious defensive code works through a simple yet effective mechanism:
- The payload is delivered as an encrypted HTML file.
- The file self-decrypts
- A script triggers to generate 10 billion instances of letter “H”.
- The page balloons to over 10GB in size
- The crawler crashes due to memory exhaustion.
From the pen of Ache (author): “I had several ideas. First, since it’s an HTML page, we start with the HTML5 doctype. Then we try to fit the 10 MB of identical characters. I first attempted to use HTML classes, which can contain anything, but quickly the HTML comment solution seemed most practical. So, I set up a small shell script (in fish) to create an HTML file with a 10 MB ‘H’ comment.”
Testing has shown this technique effectively crashes major browsers and crawler systems:
- Firefox: Fails with
NS_ERROR_OUT_OF_MEMORY - Chrome: Crashes via
SIGKILL - Selenium-based crawlers: Complete system failure
Implications for Development Teams
These developments signal a new era in web architecture where defensive programming against AI crawlers becomes crucial. Development teams need to:
- Evaluate their current crawler protection strategies.
- Consider implementing progressive defense mechanisms.
- Monitor server loads for suspicious crawler activity.
- Balance accessibility for legitimate bots while defending against aggressive AI crawlers.
As AI companies continue aggressive data collection practices, we can expect more innovative defensive techniques from developers. The HTML bomb and Labyrinth are just the beginning of an evolving (and sometimes devious 🙂) technical chess game between web ecosystems and AI crawlers.
Photo credits: Published on May 24, 2020 by Susan Q Yin > https://unsplash.com/photos/people-sitting-on-white-concrete-stairs-Ctaj_HCqW84
Ex QBASIC developer that ventured into a web world in 2007. Leading a team of like-minded Open Source aficionados that love design, code and a pinch of BBQ. Currently writing a book that explains why ‘coding is the easier part’ of our field.

